Data Implosion and not Explosion
I was planning on writing this article a while ago but never came down to it.... but I do have some time on my hands to write about how data has changed over the years. Nowadays data has been imploding and what I want to infer from implosion is that the manner in which data is being collated and published to end users with various transformations along the way creates a sense of cause and effect. You have massive data-sets but the information from this can be co-related in so many different ways that eventually one is unable to figure out how to go about getting the required information onto the end user's field of vision. Let us consider Big Data solutions....now whenever we feel that the volume of data has reached its significant end in terms of storage limitations we can go about introducing a solution (a big data solution) in order to contain the explosion and ensure that there is no data loss.... hence in this case we can always ensure that in the eventuality of a massive uptake in terms of data we can always control the size limitations by doing something concrete. But now comes the important aspect of how multiple streams of well contained data actually bump into each other to try and make information ambiguous to end users. Let us consider a database which contains the list of movies released in the past 5 years..... This is a massive amount of data but we still have containers in place to collect it. Now lets say we need to figure out which were successful (not only in terms of monetary aspects) and which were not. Initially this sounds simple and we think that performing this endeavor is going to be easy but as we look into the data, there are so many metrics which need to be considered here:
A] Box Office Revenue per region
B] Number of Theaters released in per region
C] Actors in the movie
D] Production Budget
E] Director of the Movie
F] Studio responsible for the movie
G] Genre of the movie
H] Region based dissemination of people who watch the particular genre
I] Video Rentals and Digital sales
And the list goes on.... even though all these data points are present it is still difficult to actually decipher the data and figure out which movie can be considered a success (box office, critically acclaimed, fan acclaimed etc...) or not because the data being stored is actually imploding at such a massive scale that it becomes in-deterministic to even collate meaningful representation of data from the container.
Example here:
Now the important aspect over here is to pre-determine what scenario one can gain from the massive volume of data and create a standard or norm which will be the end all for all metrics guidelines. This eventually will have to be a criteria decided among the masses and not an individual entity which comes back to my earlier statement that Data is imploding at a massive rate and not exploding. We need to introduce implosion mechanisms and maybe that will eventually be a future job by itself. Think about it--> Data Implosion Handler @ xyz co..... interesting yet is eventually bound to happen.
A] Box Office Revenue per region
B] Number of Theaters released in per region
C] Actors in the movie
D] Production Budget
E] Director of the Movie
F] Studio responsible for the movie
G] Genre of the movie
H] Region based dissemination of people who watch the particular genre
I] Video Rentals and Digital sales
And the list goes on.... even though all these data points are present it is still difficult to actually decipher the data and figure out which movie can be considered a success (box office, critically acclaimed, fan acclaimed etc...) or not because the data being stored is actually imploding at such a massive scale that it becomes in-deterministic to even collate meaningful representation of data from the container.
Example here:
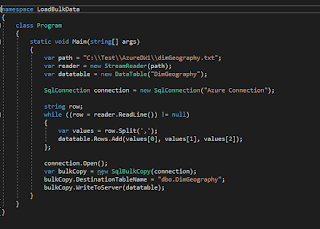
 |
| The above figure showcases how the metrics are gathered and the manner in which they collide |
 |
| Even Creating hierarchies becomes an incredible effort |
Now the important aspect over here is to pre-determine what scenario one can gain from the massive volume of data and create a standard or norm which will be the end all for all metrics guidelines. This eventually will have to be a criteria decided among the masses and not an individual entity which comes back to my earlier statement that Data is imploding at a massive rate and not exploding. We need to introduce implosion mechanisms and maybe that will eventually be a future job by itself. Think about it--> Data Implosion Handler @ xyz co..... interesting yet is eventually bound to happen.
Comments