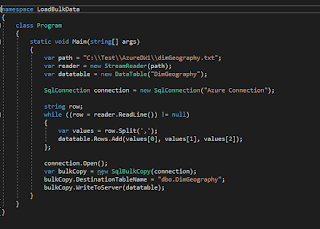
Modern Day Data Warehousing

With ever growing data volumes and the need to necessitate a faster approach into making rapid decisions on your data sets, numerous technologies have emerged in the past 5 years trying to blend the transactional pipelines, the data storage and the analytics together. The modern day data warehouse consists of dumping the data into more of a containerized approach catering away from the traditional star and snowflake schemas of the past. Not that these data warehouse schemas have been extinguished but more in tune with rapid assembly and disassembly of data in containers. The core aspect is to whether to de-containerize the data as soon as it comes into our storage layer or go about doing it in an adhoc fashion with your containers being pipelined further into data virtualization stores, data marts or even just reporting on top of the data brought into the data lake, a virtualized data warehouse, an in memory data mart etc... Almost all modern day architectures have started mo