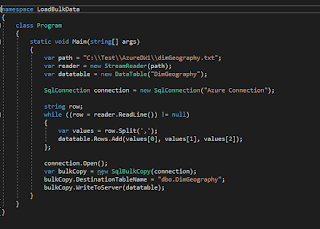
Now there are a lot of reasons why SSIS needs to be leveraged for loading data into the Azure DW platform. Even though Polybase and Azure Data factory are the core criteria's, here are the templates for the SSIS script task that were leveraged to load data (full and incremental into Azure DW) for a specific customer rather than using the data flow task: SSIS Full Load script : SSIS Incremental Load script : There are a few reasons for this approach and one of them being that the existing package was using a similar structure and one not to be deviated from. The other being that some key logging aspects needed to be handled in a Legacy platform that could not be decommissioned at that time.
I would like to consider myself as some sort of a prodigy (ahem!!! cough persisting for some time). This is my entry into the ET prodigy contest that took place last month. I must say I could have presented my understanding better but I had to follow the competition guidelines to the "T". Here it is: Sustain World (SW) provides services towards existing small scale ventures that have a foothold in the market place or to educate individuals or institutes and channeling their energy into setting up their businesses. The maximum acceptable annual income of its target audience would be 45,000 Indian Rupees(INR). The variable costs for Sustain world to come into existence would be somewhere between 4 lakh INR. Now there is an extremely high probability that most of the small scale ventures undertaken by individuals in the case of SW will never evolve from the proof of concept stage or might die in the nascent stages of creation. SW more or less will have a well sustained and aggr...
Using Rhino-ETL ( a C# based) framework for developing standard ETL's is pretty easy and one can do a lot of fun stuff with the underlying source data. I just wrote up a quick console app to generate data into a text file and push the same data into a table in SQL Server as well as an external file. Here are the following steps (for the external file push): 1. Create a new C# console application solution in Visual Studio. 2. Target the .Net framework as shown in the below screen shot in your project properties:- 3. Create 3 Sub Folders underneath your project as shown in the following screen shot DataObjects --> Contains the class files associated with each and every table/file in your environment. Example:- if your source file contains student data, then you would create a class file called Student with the individual properties (in relation to the properties) exposed (nouns). Operations --> This primarily contains the class files that contain the activities (a...

Comments